Did you know that you can navigate the posts by swiping left and right?
Traffic sign detection and mapping
Introduction
I worked for Dr. Tsai as Graduate Research Assistant (GRA) for 20 months. I spend most of this time working on a sign mapping project for SF-express and Georgia DOT. As you can imagine this project is a bit large to be described quickly here. Basically for this project I was given a video and a GPS log recorded from a smartphone and I had to produce a map of the traffic sign visible on the video.
To achieve this the process was divided into multiple tasks. The most important of them being: detection, classification, tracking and distance estimation. Multiple student helped me to work on this project, but most of them stayed only for one semester and so at the end I did work on nearly all the different part of the project. In this document I will only mention the work I did myself.
I won’t be able to share with you most of the code for this project, as this code is not publicly available. Some side repository are over available, I will provide link to them when possible.
Packaging
One of the main task I had to work on, was to package all the step into one single application for the final delivery. Thanks to my software development background I really enjoyed that task, making it easy to maintain and extend, modular and working on command line or with a UI.
Traffic sign detection

Detection is the most challenging part of this project, getting the highest precision and recall while keeping a low latency was a hard target to reach. Another student did work on this using Faster-RCNN, however this approach was shown to be slow and not very accurate. To solve this issues I decided to switch to Yolo, with a different training strategy.
The training strategy I used here was to split the process in two part, detection and classification. While Yolo can tackle both at the same time, but that require lot of data for training and high resolution images at run time. The difference between a speed limit 60 and 80 is not always easy to see when the image is blurred, even for an human. In addition signs are not common and do you really want to miss speed limit 5, because you do not have example of it in your data?
I choose to divide the sign in super category for training, using there global shape to group them. This allowed me to reduce the input resolution, reduce the class imbalance and improve the global precision and recall. Improving the accuracy also required a lot of work to review at fix the annotations done by other students. A boring and time consuming process.
To ensure the best run time possible I used the darknet C/C++ library. I wrote a custom runner in C++ using multi-threading to ensure no other task slow the network prediction. Everything was then packaged to be call in Python thanks to CPython.
The modification I made to the code and the configuration file for training, with fine tuned anchors and input size can be found on my fork.
classification
Classification is less challenging than detection, during this project a classical one shot DNN classifier was used, with satisfying results. However, lot of improvement could be done because of class imbalance or the large number of classes for example. This improvements are part of the sign classification project.
Source for training the classification DNN can be found here.
Distance estimation
One of the crucial step for an accurate traffic sign mapping is to estimate the distance and direction of the sign from the camera, in order to interpolate the camera’s GPS correctly. To perform this we used several methods, including Structure From Motion (SFM) and visual SLAM that I implemented.
SFM

In this case the goal is to reconstruct a 3D point cloud of the environment around the camera. Then extract the position of the sign by getting the 3D point corresponding to pixels of the sign.
To do that I heavily used OpenSFM from Mapillary. This allowed me to get high accuracy reconstruction without re-implementing all the algorithm myself. I only needed some pre-processing to generate the right data structure and post processing to extract the results I wanted.
An issue that was encountered is that OpenSFM consider the scene to be static. However, on most of out image there were traffic with moving cars around the camera, leading sometimes to a 3D reconstruction of the car instead of the signs. To prevent that, I use tiny-Yolo, to run a quick vehicle detection on the image, and mask them.
This method is obviously not the most efficient way to achieve this result. However, it was easy to implement and very accurate, much more accurate than the camera GPS in fact. It was then a good base to compare with other methods.
Visual Slam
In this second case the goal is to use visual SLAM to compute an accurate movement of the camera between the frames and use this plus the position of the sign on the image to deduce the position of the sign.
I relied on ORBSLAM2 for the visual SLAM part and included some C++ code to make it run on our data and interpolate the sign position. This process is much faster than SFM, but still as some drawback. One of them is that as SLAM is designed for real time usage, it does not go back to the previous frame and so may not initialize correctly. Shaky and blur frame can make it loss track.
In conclusion this method is much faster than SFM, but as some inconvenient, while still being very heavy for this task. Simpler approach were also explored by other student, such methods always rely on lot of strong assumptions making the process less accurate at the benefit of negligible run time.
My fork of the ORBSLAM2 repository is available here.
Qa/Qc
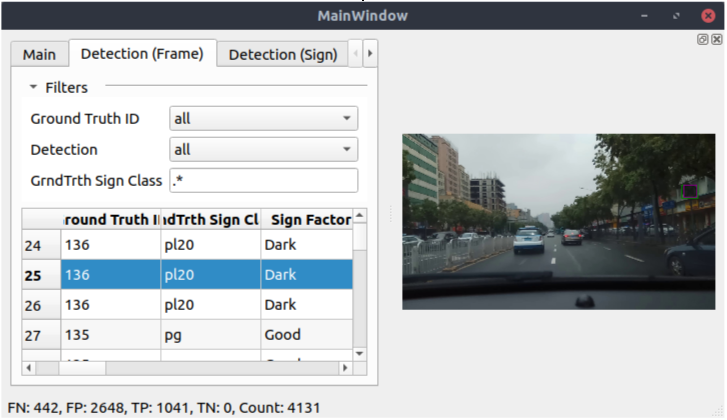
For this project I also created a tool that compare the results of each steps with the ground truth, to compute accuracy metrics and quickly extract and visualize problematic cases. This tool is build in Python around a basic pyQt UI with some algorithm and SQL request to extract the data.
If this tool was extremely useful in the early days of the project, it became less and less used as the time passed, for a very simple reason, ground truth is expansive and we were not able to afford getting it for new data.
Conclusion
I learned a lot during that project that allowed me to improve on lot of different skills. From software development to machine learning and computer vision. It also give me a lot grounding in what annotating data mean and how painful it can be. It was also for me the occasion to interact directly with the client who is going to use this software, getting to know his very generic request and impossible goals. I also learned a lot from managing this project from end to end and working with new students every semester. Looking back at it was great experience.

Nicolas Six is a Computer Science engineer passionate about machine learning and robotic.