Did you know that you can navigate the posts by swiping left and right?
Traffic sign detection on mobile device
Introduction
This work started by a simple conclusion: state of the art are very good at detecting complex object in complex environment. However, they need a lot of resources to run. While traffic sign are made to be detected, they have bright colors, clear shape, are always seen from the same angle… Is it needed to have a complex feature extractor to properly detect them? In this work I focused of US warning sign, but it’s easy to extant and reproduce the results to other kind of signs.
This project was part of my Master thesis at the Georgia Institute of Technology. My goal was to improve over my GRA work, and bring the traffic sign detection directly to a smartphone, saving energy, storage space and making the process much easier to run. If you want more detail about the global project, please check my post here.
In this page I will try to summarize months of work in a readable format. However, for more detailed information I advise you to check my dissertation and slides.
Idea
Object complexity
As already stated in the introduction, traffic sign should be much easier to detect than let say an owl, which is one of the class of the MS COCO dataset from which come the image bellow.

On the other side, even on poor conditions, traffic sign are always very easy to see.

To make our Convolutionnal Neural Network (CNN) faster, we can hope that this will translate into features that are easier to learn by the network and more importantly require less filters and less layers to be properly extracted.
For a quick demonstration of how easy it is to get good feature extraction for traffic sign, let use the following image as a base.

Now generate some very basic yellow edges detection filters.

Applying them on the image directly extract all the important features of the sign with very few noise, as you can see on the figure bellow.

This is obviously only a toy example and if building hand crafted filters for traffic sign detection have been the focus of lot of research in the past the results have always been far from perfect.
However, it does show that using over 50 layers as a feature extraction backbone does not make sens in a traffic sign context.
Object shape
Now that we beleive that the object we are look at are not very complex, can we take advantage of any other features to make the detection easier?
State of the art one shot object detection CNN, as of 2020, use anchors box to set base shape of the objects the network is trying to detect. Bellow is an illustration of how Yolo v3 do it.
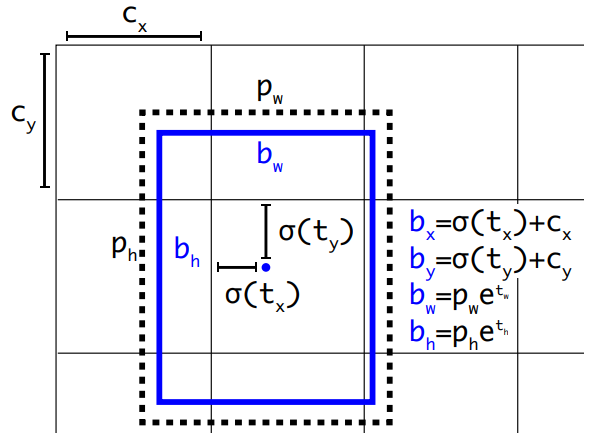
So for each prediction, Yolo v3 predict, in addition to the object class, four values. To predict the offset to the center of the detection cell and to scale the anchor shape to the best shape.
Let’s look at the object we are trying to detect:

You can see that this object always fit very well into a square bounding box. Because of there usage on the road, we always saw them from the front, with very few perspective distortion. Making the two parameters for sizing the the anchor redundant.
In addition, in this study we took the assumption that size and position are hard to predict for a CNN. This come from observation of the accuracy of tiny-Yolo compared to Yolo, most of the time the prediction made by tiny-Yolo are correct, but the bounding box is not very accurate. In our case we don’t really want pixel accurate bounding box. We just want to detect if there is a traffic sign on the image, have an approximate position and size. If we want more detail we can run a post process with this information, but being able to quickly filter over 90% of the frame that does not have a sign is crucial for real life application.
With that in mind, we decided not to predict this four different parameters and just to use the anchor directly. Using five different anchors allowed us to get a very good overlap with the signs on the images.
Datas
The data used for this study are of two kind. First, we used real data profited by the lab, but as this data are limited in quantity and cost a lot to get, I also generated some artificial data, used as a first training set, before fine tuning on the real data.
Real Data
This dataset of 8,719 image manually annotated from image recorded in Georgia and surrounding area. The image were collected using two different means, a smartphone camera or a sensing vehicle with specialized equipment. Please refer to the Appendix of my thesis for more information.
Artificial data
Even with data heavy augmentation and dropout, 8,719 image are not enough to train a CNN from scratch. Instead of training the backbone on a classical image classification task, such as ImageNet, as it is usually done, we chose here to generate artificial data for two reasons. First, because we can generate this kind of data easily. Second, because using this data allow us to specialize the filters directly and so allow us to use as few filter as possible right at the beginning.
To generate this data, we chose a very basic approach. We fill an image with random polygons with colors sampled from the color distribution of the real data. On top of this image we draw a set of yellow square rotated by 45 degree, as well as a set of not rotated square as negative example. An example of an image generated that way is given bellow.

This image is not designed to be realistic. However, it does allow to train a yellow square detector on a noisy background, which is what we care about at that point.
Lot of implementation details are not given here, my thesis will give you more information, you can also check the generation code here.
Architecture
The architecture used in this work is very similar to the one of SSD, with a loss function directly derived from it and a custom backbone. A complete description of this architecture is out of scope of this article. However, interested reader are strongly encouraged to check my thesis dissertation or the source code.
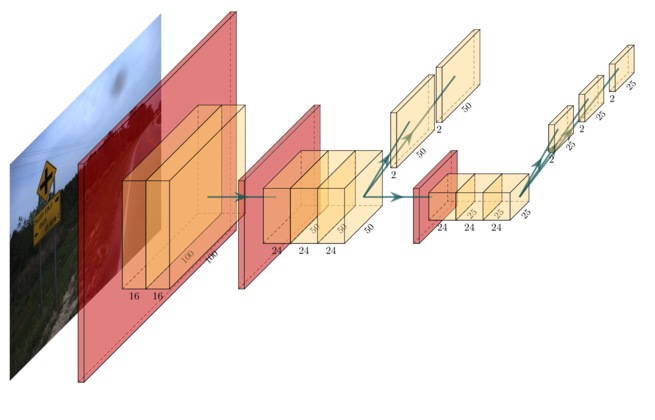
The image above is a graphical representation of the final architecture. Each yellow block represent a layer, the red region being the input size when strides are involved. You can see the five final output layers, one for each anchor.
During this study different kind of block were tested. From the classical 2D convolution to residual convolution and inverted residual block. But the residual convolution showed the best results in our experiment and is the one we chose to use here.
Results
We will now give you a quick overview of the results we get from this model. As the focus of this study is to reach the best speed possible, let me start by presenting the accuracy evolution with speed of this model. We are going to use here two different accuracy metrics, map@25 and map@50 (mean average precision at 25% IoU and 50% IoU respectively). We here use very low IoU threshold because of our problem definition, according to our assumption we don’t target very accurate bounding box.
As a comparison, we also plot the value for tiny-Yolo v3, trained on the same dataset.
The different point in the plot represent different input size for tiny-Yolo and different filter count for our architecture.
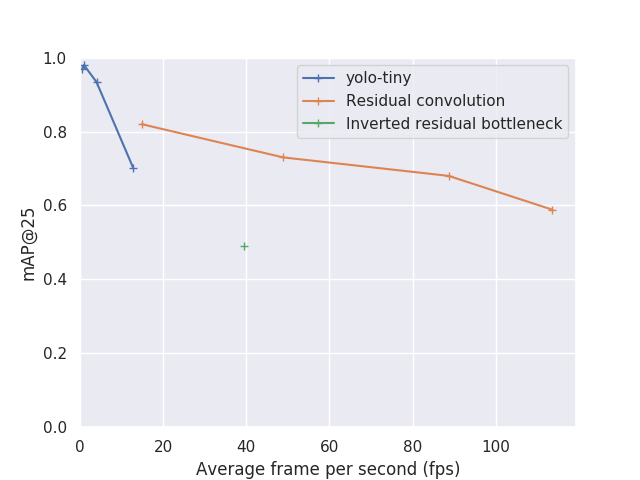
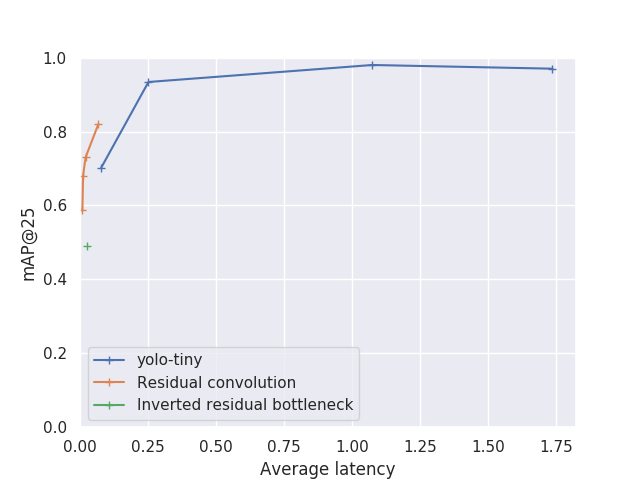
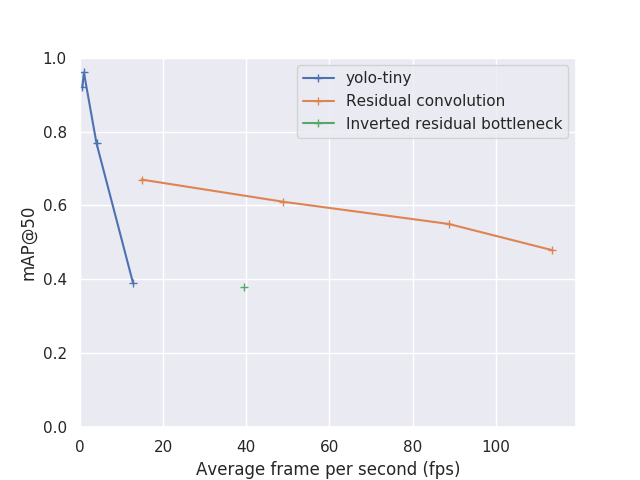
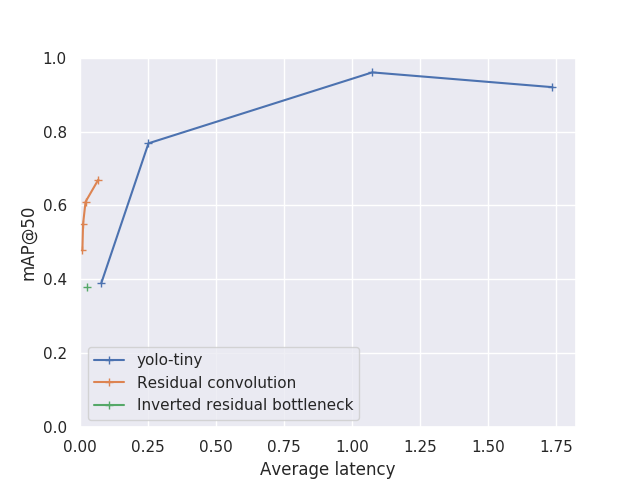
You can see that if our architecture does not surpass Yolo accuracy. It does reach comparable map score while being an order of magnitude faster.
To give you a better idea of what this results mean, bellow are some example of detection as done by the architecture.

Case of a warning sign not detected on a curve.

Case of a sign detected while not being of the right class.

Case of an obstructed sign correctly detected.
More example example and comment about them are available for the interested reader in my thesis dissertation.
Conclusion
I really enjoyed working on this problem as it allowed me to take the time to thing about a complete architecture, taking into account the specific problem I was solving and the hardware I was given to use. It also allowed me to better see the effect of multiple parameters such as dropout, weight regularization, loss, activation function… Skills that I’m looking forward to continue to use in the future.

Nicolas Six is a Computer Science engineer passionate about machine learning and robotic.